题目总结
买卖股票的最佳时机系列
Ⅰ 121
单调栈的题解以及系列题目
单调栈的应用场景 当你需要高效率查询某个位置左右两侧比他大(或小)的数的位置的时候
似乎也用双指针来解决这个问题
这个题解真的很不错
本题最妙的方法 其实是 dp思想的优化
腐烂的橘子似乎对动归的理解比较深,有时间可以看看他的系列
* [ ] [背包的理解](https://leetcode-cn.com/problems/coin-lcci/solution/bei-bao-jiu-jiang-ge-ren-yi-jian-da-jia-fen-xiang-/)
Ⅱ 122
- 这个精选题解给出了股票交易的一系列算法
Ⅲ 123
我想写成k在第一维度,day在第二维度的,更像是背包/阶段划分的思想
有人说就是个背包,其实我觉得就是最后的形式上比较像而已,没有必要强行联想…
不过可以看下人家怎么理解背包的…2333
压缩要倒着写,自己写的时候要注意下
但是这篇分析了为什么可以正序
“然计算过程中的一个变量值不同,但这一个值的差异并不会影响最终结果” 有点意思
需要注意初始化,尤其是下面的题目,K>=N/2的情况要注意
Ⅳ 188
不停看到有人用哨兵/N指针的思路…看看呢
309 含冷冻期的买卖
714 含手续费的买卖
打家劫舍系列
打家劫舍Ⅰ
周植:最基础的解法: dp[stage][0/1] & dp[i]代表偷了前i家,且一定偷第i家的(解法复杂)
Krahets:进阶版 虽然想起来比较难,但是时空复杂度都比较低
dp[i]代表偷前i家的最大值,dp[i] = max( dp[i-1],dp[i-2]+nums[i] )
- ==Krahet的题解都不错,有空可以都看看==
总结的经验就是:
像这种隔着选的问题,虽然最naive(其实也不很naive 233)的解法是要将当前阶段的决策融入状态中标明的( dp[stage][0/1] ),但其实只有两种选择的情况下,不标明也可以233…
但我个人的建议还是要标明…因为只有在 只有两种选择的情况下才可以进化成Krahet的形式。如果选择多了的话,其实Krahet的方式不是通用的。
打家劫舍Ⅱ
化解为两个单排,问题是:存不存在两个单排的最优解都是没有取到两端的(也就是 optimal[:-1]的解 不包括num[0] , optimal[1:]的解不包括num[-1],所以其实第一个和最后一个都没取 )
或者另一个思路挺好:第一个和最后一个不能共存,所以就是两种情况的最大值:
可以取第一个,那么最后一个肯定不能取
把最后一个数设置为0,然后对整个数组进行’打家劫舍Ⅰ’的运算。因为最后一个设置为0,所以就相当于没有取(就算被选中了,也可以删去)。–》那么其实最优解 与nums[:-1]得到的最优解是一样的,所以对nums[:-1]的部分数组进行’打家劫舍Ⅰ’的运算即可。
至于最优解中到底包不包含第一个,其实都可以。我们是要防止 万一最优解中有第一个的情况,此时最后一个坚决不能取。
那有没有可能最优解中,没取第一个(取了第二个),也没取最后一个nums[:-1]中的最后一个(也就是原序列的倒数第二个),那么此时完全可以取原序列中的最后一个,且不会产生冲突。【注意,这种情况就属于下面的情况里面包含了】
一定不取第一个,但可以取最后一个
把第一个数设置为0,然后对整个数组进行’打家劫舍Ⅰ’的运算。因为第一个一个设置为0,所以就相当于没有取(就算被选中了,也可以删去)。–》那么其实最优解 与nums[1:]得到的最优解是一样的,所以对nums[1:]的部分数组进行’打家劫舍Ⅰ’的运算即可。
如果合并后的最优解是头尾都没选,那就说明 着实不需要这两个2333
打家劫舍Ⅲ 【树形dp】==!!没做完&整理==
403Frog Jump 青蛙过河
官方讲解还是很靠谱的!思路从易到难
- 动态规划+哈希表优化
- 可行性问题,而不是求最优解问题
最简单的能想到的就是 dp[stone][action],其中stone和action都是 [1:max(stones)] , 因为我们在某个stone处,其实我们也不知道前面一步具体是多少。这个的问题是,直接out of memory。把dp矩阵打印出来也可以发现大部分都是False,which means是稀疏矩阵。也就是说我们的阶段和状态定义的不好。
太可怕了,这个一开始的想法也太愚蠢了吧…
我们的阶段实际上就只有stones数组里面的几个数值,并不是连续值,所以阶段就是[stone in stones]。紧接着就是action的设计考量:
想法1
action实际上不会超过1100(每步只会增加1,一共最多输入1100个数,还包括0)。但这个想法就是有点浪费空间,因为还是很多action是取不到的。。 但这里的更新方式就比较值得玩味了,是
for i in range(len(stones)): for j in range(len(i)+1), 而不是常规的
i in range(len(stones)): for j in range(action_lens)```, 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
所以就比较难想。但是如果按照常规的for循环更新,就会设计到查找的优化。下文会体现。
* 想法2
一个地方只能从前面的某个石子跳过来,which means也不是连续整数值可选,所以其实也只有O(num(stones))的可选项。所以又回到打家劫舍的问题的里面去了: 前i个stone,所以设计为dp\[stone][stone]表示的就是从stone_idx2跳到stone_idx1是否可行。如下,但是每次状态转移,需要搜索stones的list( O(n) ),最后就是**<u>O(n^3)</u>**的复杂度了--> O(10\^9)直接超时。(可以用一些小trick优化到O(n^2)([version2](https://github.com/hexi519/leetcode_prac/blob/666e94e8c76107980729f0b23a9e621f77671dfb/403FrogJump.py#L39)),但可以看到由于常数项比较大,还是跟下面常用方法2,也就是version3差了不少。)
**<u>改进思路: 降低查找的复杂度</u>**
* [ ] [常用方法1](https://leetcode.com/problems/frog-jump/discuss/223586/Python-solution):二分搜索,**<u>O(n^3) --> O(n^2*logn)</u>**
* [常用方法2](https://github.com/hexi519/leetcode_prac/blob/666e94e8c76107980729f0b23a9e621f77671dfb/403FrogJump.py#L65):使用额外的、低查找开销的数据结构存储经常要查找的东西。这里使用hashMap存储可用的action, 所以每次就不是搜数组,而是搜一个集合,且由于只存前一步可达的,也就是有效的action,所以相当于剪了很多枝。O(n\^3)-->O(n^2),且前面的常熟会比较低
----
==区间dp??==
* [413 等差数列划分题解](https://leetcode-cn.com/problems/arithmetic-slices/solution/dong-tai-gui-hua-by-dream_day-2/) 这个虽然不是精选,但是感觉还不错
> 以A[i]结尾的子等差序>列的**头指针位置**就比以A[i-1]结尾的子等差序列的**头指针位置**的**选择多一位**,这样也就dp[i] = 1 + dp[i-1]
* [x] ==446 等差数列划分2== (做是做完了,题目也理解完了,但是感觉很生硬,后续还要复盘一遍)
* [这个对为什么用hash Table 讲得很到位](https://www.cnblogs.com/grandyang/p/6057934.html)
* 什么时候用hash table来优化...就是一个状态跟之前的稀疏状态集有关联的时候 用于优化存储
* 经验法则就是:处理连续的子问题的时候,要找O(n)的解; 处理非连续的子问题的时候,要找O(n^2^)的解
----
**<u>二维动态规划</u>**
* [x] 64. Minimum Path Sum (Medium)
* [x] 542. 01 Matrix (Medium) 求出每个1距离最近的0的距离长度
* 动归的思路是可以,[官方题解](https://leetcode-cn.com/problems/01-matrix/solution/01ju-zhen-by-leetcode-solution/)给出的一个insight就是:矩阵上某个点的信息传播,可以只从左上方和右下方进行传播。
* 但我觉得这里,官方题解给的bfs思路更好理解一些...
* [x] 221. [最大正方形](https://leetcode-cn.com/problems/maximal-square/) & 1277[统计全为 1 的正方形子矩阵](https://leetcode-cn.com/problems/count-square-submatrices-with-all-ones/)
二维的,跟矩阵有关的,都是dp\[i][j] 表示(i,j)为一个范围的边界点的一个值(这里就是以(i,j)为右下角的矩阵的最大边长)。
至于为什么是右下角而不是左上角或者其他角,其实都可以,选右下角主要是为了可以方便矩阵从第一行第一个,往右、往下遍历,这个比较符合人类的直觉。
* 一次递归要用到左边,上面,左上角的信息,可以用两个一维数组压缩空间,还可以用一个一维+两个临时变量进行压缩
* [ ] 就是221不知道为啥越压缩,时空性能越差....
* [ ] 先看下[人家](https://leetcode.com/problems/count-square-submatrices-with-all-ones/discuss/643429/Python-DP-Solution-%2B-Thinking-Process-Diagrams-(O(mn)-runtime-O(1)-space)怎么做性能优化的吧...说不定是我优化的方式错了...
* 至于为什么这么递推,可以看下[这个题解](https://leetcode-cn.com/problems/count-square-submatrices-with-all-ones/solution/tong-ji-quan-wei-1-de-zheng-fang-xing-zi-ju-zhen-2/)的简单证明
* 1277的思路我觉得看[这个讲解](https://leetcode-cn.com/problems/count-square-submatrices-with-all-ones/solution/tong-ji-quan-wei-1-de-zheng-fang-xing-zi-ju-zhen-f/)更靠谱...
> $\underset{i}{\sum}$宽度为 i 的正方形的个数
* 84
* 85
* 小总结
* 一般的递归就是考虑左边、上面、左上,再难一点就是从多个角度传递消息(目前221可以看出来从左上和右下两个角度传递消息就差不多了),但这种实际上也不是很好想,所以可以退而求其次:
* 其实矩阵也是一种规整的图,用搜索的思想也很不错
* 如果想到是的dfs,大概率就是一个比较差的暴力,想办法剪枝 或者 进化/优化到dp
* 可以往bfs想,一般都还不错 ( e.g.1277 )
---
**<u>分割类问题</u>**
* 279 perfect squares
* 动归
其实我觉得就是一个多重背包,大家讲得那么复杂...标答和[我的解法](https://raw.githubusercontent.com/hexi519/leetcode_prac/master/279PerfectSquares.py)实际上就差别就在于内外循环的顺序,但我觉得我的更好用些...
时空复杂度O( $n*\sqrt{n}$ ) 和 O(n)
* [ ] ~~这个的贪心的证明没有理解~~ 【不想学贪心了...】大部分还要证明...太烦了...
* 搜索
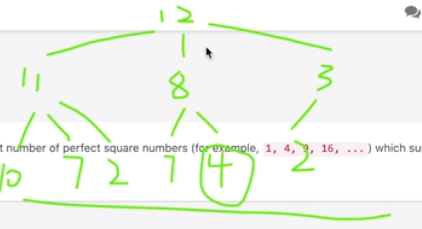
> 平时搜索练的少,但其实万物皆可搜索,所以后面做动归最好也跟上搜索的解法把... [这次](https://raw.githubusercontent.com/hexi519/leetcode_prac/master/279PerfectSquares.py)写上了
时空复杂度为O( $\sqrt{n}^h$ ) 和O(n) 这里h 不好确定,因为是树高,也就是最小需要的组合数,which我们也不好确定...
看到b站题解里面说:==如果n超过10^6^,那么空间就开不下了...这个时候别无他法就只能搜索了==
有一个在同一层的剪枝优化[]()
==都是逆着的,要想想看为什么是逆着的 ask魏知宇?==
* 字符串上的文章
* [ ] 91 解码方法
* [ ] 还有hard的95 解码方式Ⅱ还没做...
* [ ] 139 单词拆分
---
**<u>子序列问题</u>**
> 因为子序列类型的问题,穷举出所有可能的结果都不容易,而动态规划算法做的就是穷举 + 剪枝,它俩天生一对儿。所以可以说只要涉及子序列问题,十有八九都需要动态规划来解决,往这方面考虑就对了。
>
* 最长上升子序列
* [红豆薏米的b站视频](https://www.bilibili.com/video/BV17t411E7Xn/?spm_id_from=333.788.videocard.0)把O(nlogn)的思想解释的很好
最重要的是二分搜索的实现,可以参考[labuladong的小抄](https://images.weserv.nl/?url=https://labuladong.gitbook.io/algo/di-ling-zhang-bi-du-xi-lie/er-fen-cha-zhao-xiang-jie)【着实不错】,要搞清楚你是要查找某个值还是查找某个值的左/右边界就可以,在这里<u>查找的是第一个比自己的大的元素的位置(如果已有跟自己相同的元素就什么也不更新就退出)</u>。
> ==全部用左闭右闭的形式比较方便记忆==
* 变体就是最长不减子序列,这个变体也是找第一个比自己大的元素的位置(但是如果有跟自己相同的元素,不会立马退出,会继续往上界搜寻)
```python
# 最长上升
if mid == num: break
# 最长不减
if mid == num:
left=mid+1 # 继续往上界搜值得注意的是,tail数组并不是最长上升子序列!(自己可以举反例想想)
最长上升子序列(LISLIS):Longest Increasing Subsequence
最长连续序列(LCSLCS):Longest Consecutive Sequence
最长连续递增序列(LCISLCIS):Longest Continuous Increasing Subsequence
最长公共子序列(LCSLCS):Longest Common Subsequence
背包问题
==dp为什么是NP?== 感觉O(n)就可以验证啊,所以n也是n的多项式是么
416 分割等和子集
使用布尔数组,然后使用或运算,快了不少
看到有更快更省的…用bit以及位运算…
639 划分为k个相等的子集
搜索的思想…我还不太会…==感觉todo是搜索里面常用的==
600 不含连续1非负整数【第一遍做有点吃力】
实际上是数位dp
去b站上再看看数位dp的模板…
- 1147段式回文
- 双指针解法
- 贪心解法
- 1235规划兼职工作
==感觉这两个应该得好好研究下双指针问题再来做做…==
字符串系列
最长回文子串,但是我只能想到中心扩散的方式咋整… 而且还没实现完
这个讲解好详细!
这个讲解不错

